-

- ARCHIVE
MV CIMF Festival
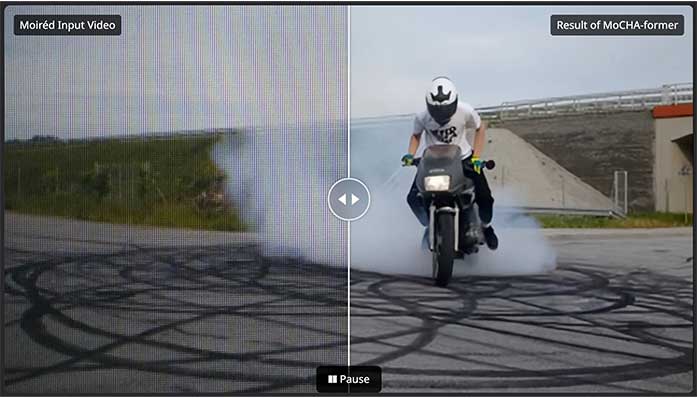
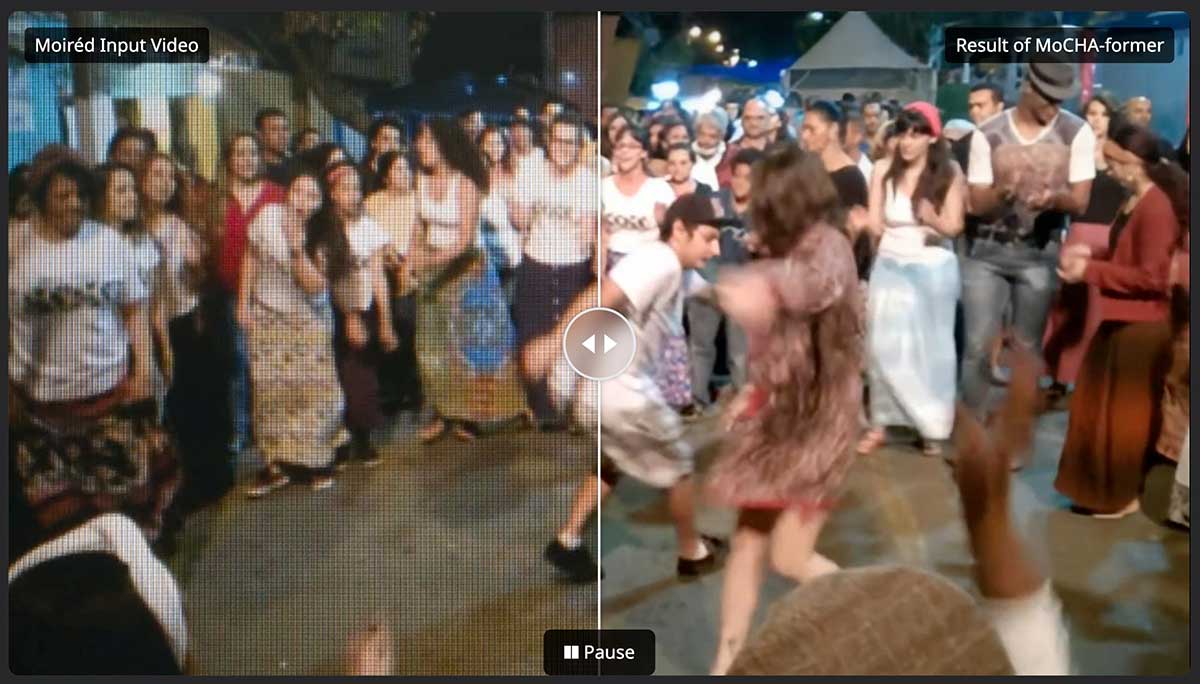
MoCHA-former: Moiré-Conditioned Hybrid Adaptive Transformer for Video Demoiréing
Jeahun Sung, Changhyun Roh, Chanho Eom, Jihyong Oh Creative Vision and Multimedia Lab
Recent advances in portable imaging have made screen capture common, but frequency aliasing between the camera CFA and display sub-pixels causes severe moiré artifacts. We propose MoCHA-former, a video demoiréing framework with two key modules: DMAD, which separates moiré from content to produce moiré-adaptive features, and STAD, which captures large-scale structures, models channel dependence, and ensures temporal consistency without explicit alignment. Evaluations on RAW and sRGB video datasets show that MoCHA-former achieves superior PSNR, SSIM, and LPIPS compared to prior methods.



중앙대학교 가상융합대학원

06974 서울특별시 동작구 흑석로 84, 중앙대학교 305관 1001호
Tel. 02-881-7386 / E-mail. caumeta@gmail.com
@ GRADUATE SCHOOL OF METAVERSE CONVERGENCE. ALL RIGHTS RESERVED.