-

- ARCHIVE
MV CIMF Festival
메타버스융합대학원 연구실(Imaging Science, Media Art, Animation, Film)의 응용기술을 산학협력에 적용한 메타버스 관련 창의적인 콘텐츠와 영상물 전시
- 일시 : 2025. 11. 5.(수)~6.(목), 10:00 ~ 17:00
- 장소 : 중앙대학교 310관 1층 로비
- 해외자문위원 : Minsu Kim(JPN), Research Scientist(Google DeepMind, Tokyo)
-
-MITIGATING-CATASTROPHICFORGETTING-WITH-DISTANCE-BASED-PROTOTYPE-LEARNING_썸네일.jpg) Imaging Science
Imaging Science<SESSION CLASS PROTOTYPE INCREMENTAL LEARNING(SCPIL) MITIGATING CATASTROPHICFORGETTING WITH DISTANCE-BASED PROTOTYPE LEARNING>
Seongsu Kim, Sangwoo Yun, Illhwan Kim, Dongheon Lee, Joonki PaikImage Processing and Intelligent System Lab
-
 Imaging Science
Imaging Science<Performance Improvement of Voxel-Based 3D Object Detection Using Distance-Based Selective Sampling >
Jihoon You, Injae Lee, Seoneun Kim, Joonki Paik Image Processing and Intelligent System Lab
-
 Imaging Science
Imaging Science<From SAM to CAMs: Exploring Segment Anything Model for Weakly Supervised Semantic Segmentation >
Hyeokjun Kweon, Kuk-Jin YoonFoundational Vision Lab
-
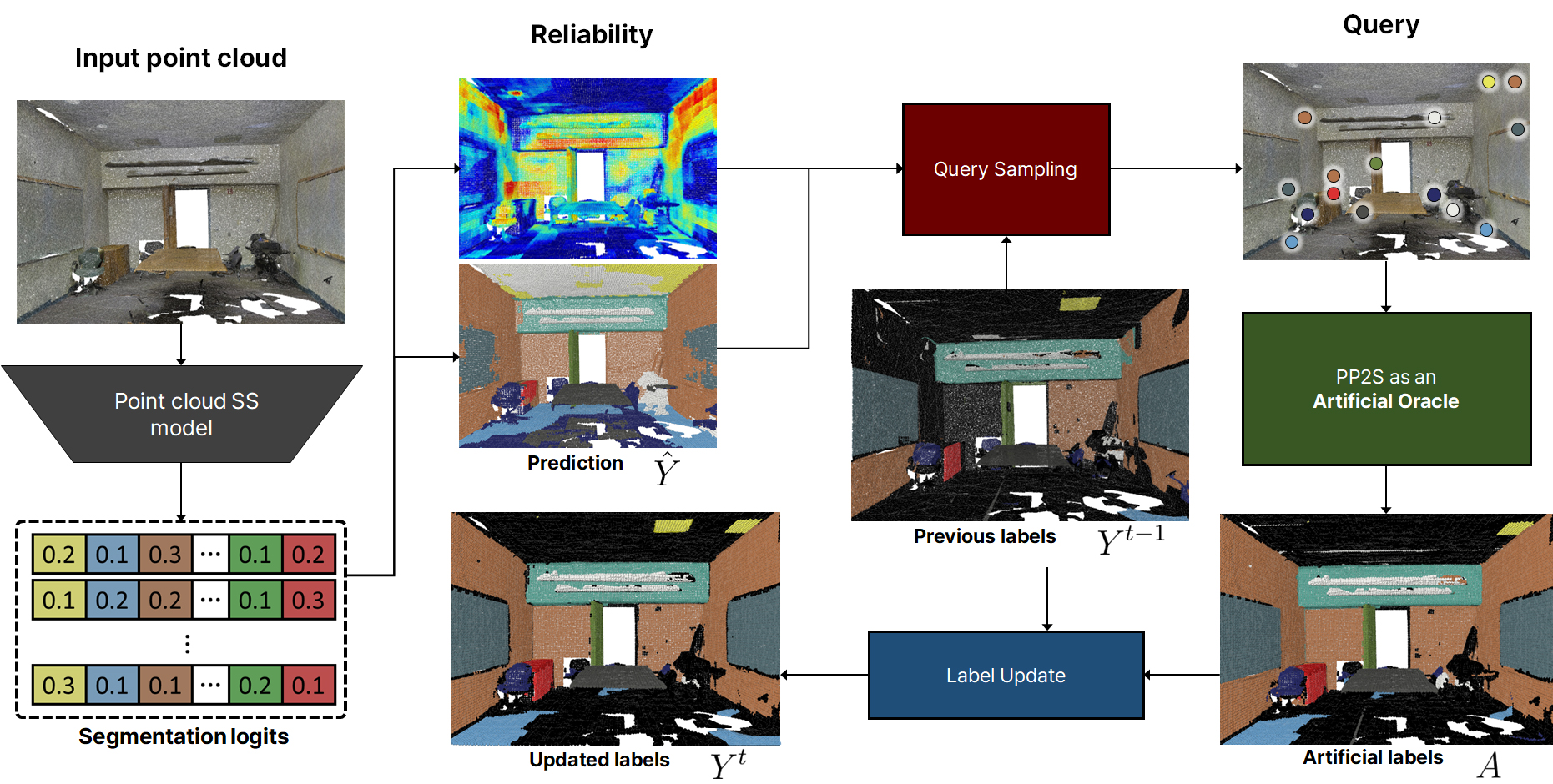 Imaging Science
Imaging Science< 3D Vision and Recognition >
Hyeokjun KweonFoundational Vision Lab
-
 Imaging Science
Imaging Science< Leveraging Text Signed Distance Function Map for Boundary-Aware Guidance in Scene Text Segmentation >
Ho Jun Kim, Hak Gu KimImmersive Reality & Intelligent Systems Lab
-
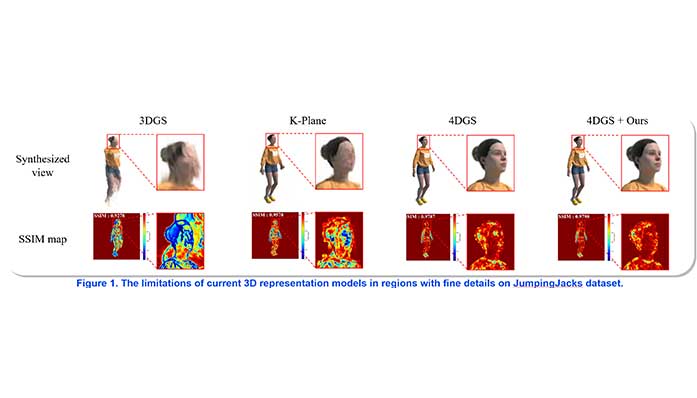 Imaging Science
Imaging Science< Enhancing 3D Scene Representation with Structural Dissimilarity-Aware Learning >
Seungjae Lee, Ho Jun Kim, Hak Gu KimImmersive Reality & Intelligent Systems Lab
-
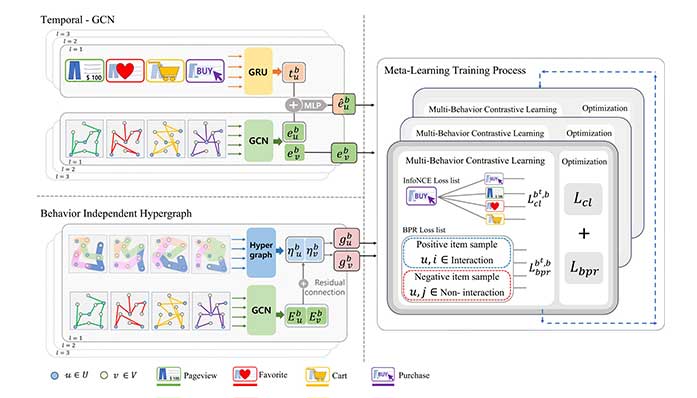 Imaging Science
Imaging Science< Hypergraph temporal multi-behavior recommendation >
Jooweon Choi , JuneHyoung Kwon , Yeonghwa Kim, YoungBin KimIntelligent Information Processing Lab
-
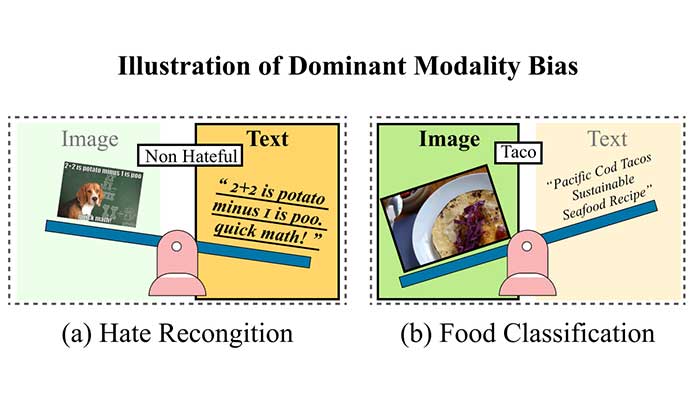 Imaging Science
Imaging Science< See-Saw Modality Balance: See Gradient, and Sew Impaired Vision-Language Balance to Mitigate Dominant Modality Bias >
JuneHyoung Kwon, MiHyeon Kim, Eunju Lee, Juhwan Choi, YoungBin KimIntelligent Information Processing Lab
-
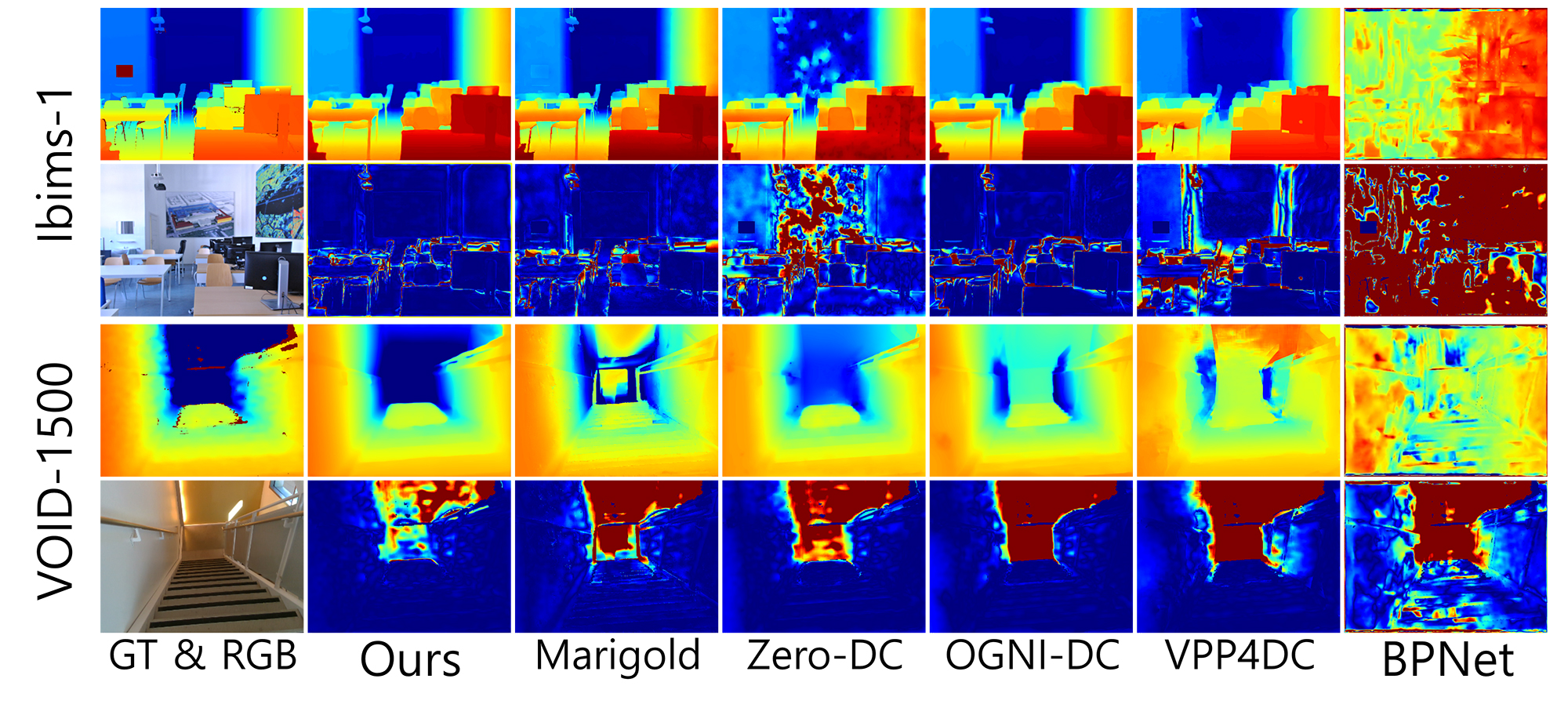 Imaging Science
Imaging Science< Depth Prompting for Sensor-agnostic Depth Estimation >
Jin-Hwi Park, Chanhwi Jeong, Junoh Lee, Hae-Gon JeonComputer Vision & Social Artificial Intelligence Lab
-
 Imaging Science
Imaging Science< What Makes Deviant Places? >
Jin-Hwi Park, Young-Jae Park, Ilyung Cheong, Junoh Lee, Young Eun Huh, Hae-Gon JeonComputer Vision & Social Artificial Intelligence Lab
-
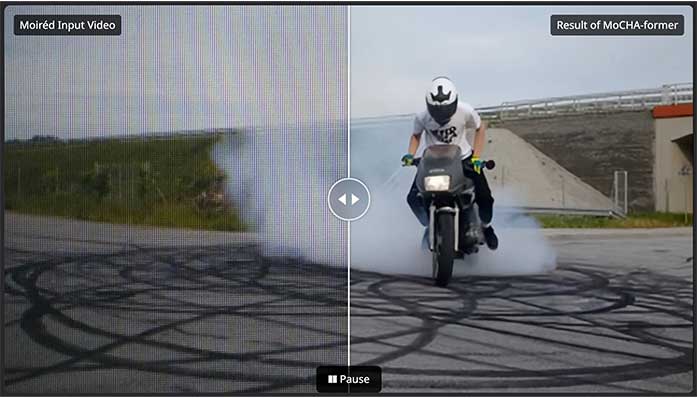 Imaging Science
Imaging Science< MoCHA-former: Moiré-Conditioned Hybrid Adaptive Transformer for Video Demoiréing >
Jeahun Sung, Changhyun Roh, Chanho Eom, Jihyong OhCreative Vision and Multimedia Lab
-
 Imaging Science
Imaging Science< FLAIR: Frequency- and Locality-Aware Implicit Neural Representations >
Sukhun Ko, Dahyeon Kye, Kyle Min, Chanho Eom, Jihyong OhCreative Vision and Multimedia Lab
-
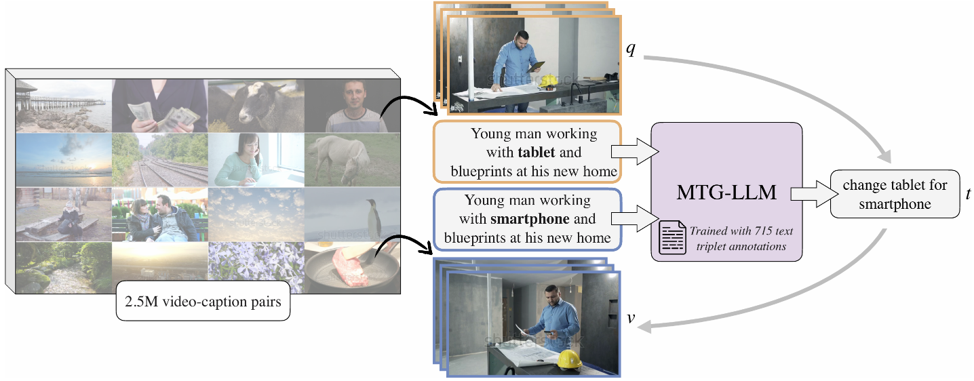 Imaging Science
Imaging Science< COVA: Text-Guided Composed Retrieval For Audio-Visual Content >
Gyuwon Han, Young Kyun Jang, Chanho EomPerceptual Artificial Intelligence Lab
-
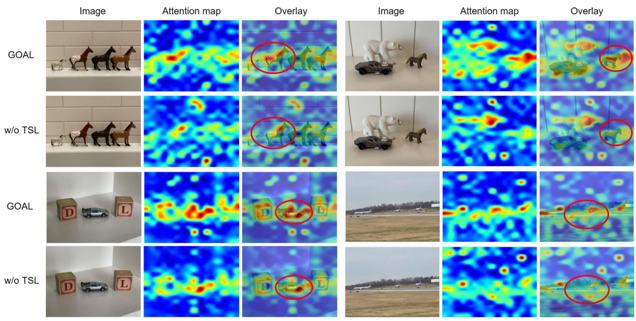 Imaging Science
Imaging Science< GOAL: Global-local Object Alignment Learning >
Hyungyu Choi, Young Kyun Jang, Chanho EomPerceptual Artificial Intelligence Lab
-
 Imaging Science
Imaging Science< SCENEDERELLA: Text-Driven 3D Scene Generation for Realistic Artboard >
Jungmin Lee, Haeun Noh, Jaeyoon Lee, Jongwon ChoiVisual Intelligence Lab
-
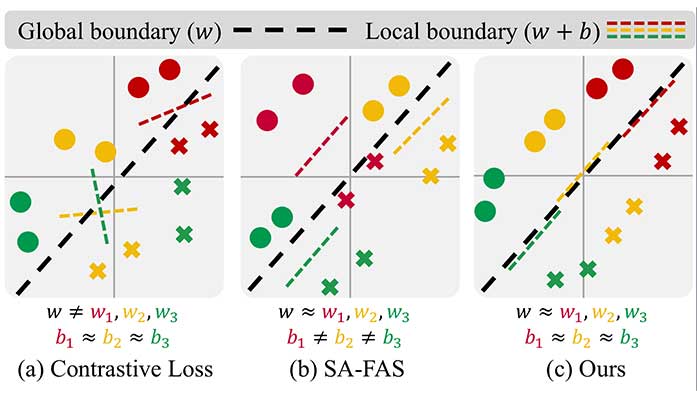 Imaging Science
Imaging Science< Group-wise Scaling and Orthogonal Decomposition for Domain-invariant Feature Extraction in Face Anti-Spoofing >
Seungjin Jung, Kanghee Lee, Yonghyun Jeong, Haeun Noh, Jungmin Lee, Jongwon ChoiVisual Intelligence Lab
-
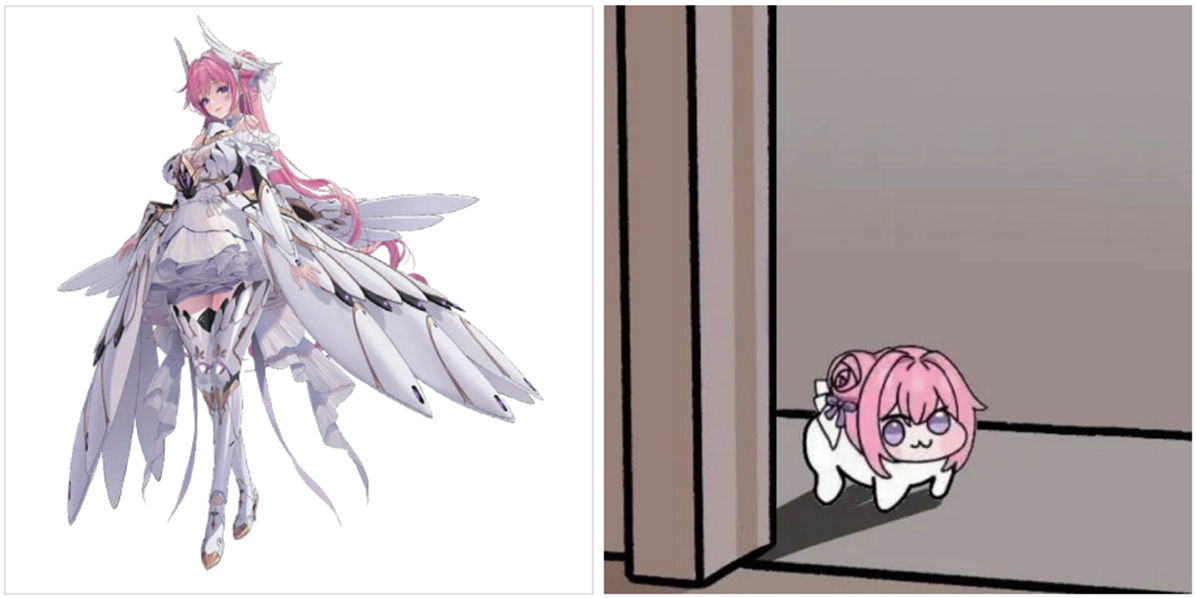 Media Art
Media Art< 게임 IP의 재매개 전략과 팬덤 2차 창작의 교차 -《승리의 여신: 니케》를 중심으로- >
이하린, 박진완Media Art Future Media Art Lab
-
 Media Art
Media Art< 사라지는 어둠의 끝에서 >
김영채, 정수아Media Art Future Media Art Lab
-
 Media Art
Media Art< ART ACCENT: Liminal Traces 경계, 그 사이로 피어나는 >
엄정원Generative Media Art Lab
-
 Media Art
Media Art< COMMOTION International Media Art Festa >
Camilla RighasGenerative Media Art Lab
-
 Animation
Animation< 예산군 10경을 주제로 한 미디어 아트 연구_ 지역의 자연과 문화를 미디어 아트로 재해석한 디지털 지역 홍보 연구 >
김성은, 김태관, 양예원, 이성경CAD Lab
-
 Animation
Animation< Synthetic Tears >
김태관CAD Lab
-
 Film
Film< AI 디에이징 기술을 활용한 사례 연구 - 드라마 <카지노>를 중심으로 >
이정민Film Making LAB
-
 Film
Film< AI 숏폼 콘텐츠 제작의 다른 측면: 뉴미디어 언어에 대한 이해와 실천 >
소원Film Making LAB
-
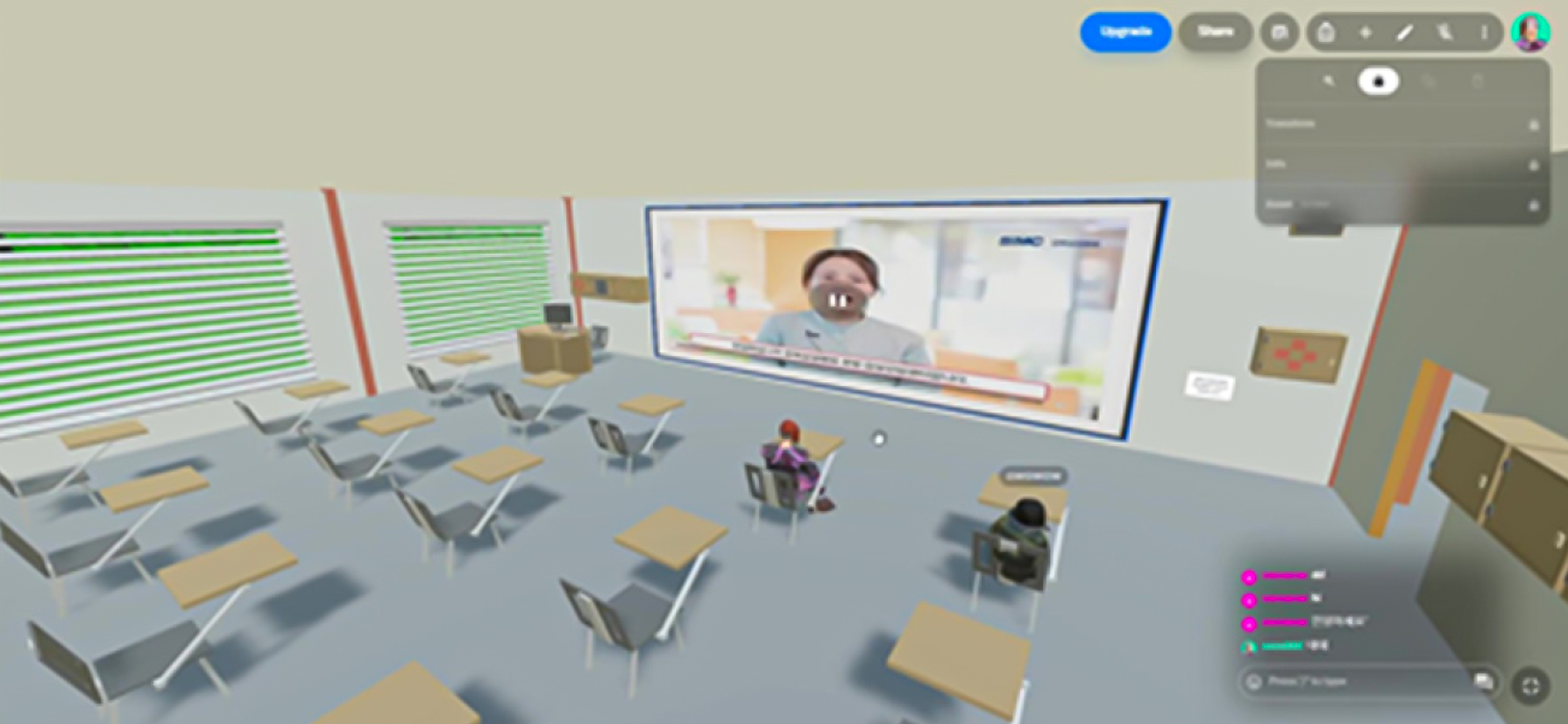 MV CFT
MV CFT< 3D Head and Body Pose Estimation 기반 갑상선 환자 재활운동 정량적 평가 및 안내 시스템 >
이승재, 김호준, 이하린MV-CFT 1팀
-
 MV CFT
MV CFT< 메타버스를 활용한 사회 문제 인식 개선 프로젝트: VR 월드 속 시각적 재현에 관한 연구 >
이승훈, 박상민, 유세혁, 임병극MV-CFT 2팀
-
 MV CFT
MV CFT< Artverse: 가상 공간 속 확장된 예술 >
박주현, 황성태, 김영채MV-CFT 3팀
06974 서울특별시 동작구 흑석로 84, 중앙대학교 305관 1001호
Tel. 02-881-7386 / E-mail. caumeta@gmail.com
@ GRADUATE SCHOOL OF METAVERSE CONVERGENCE. ALL RIGHTS RESERVED.