-

- ARCHIVE
MV CIMF Festival
COVA: Text-Guided Composed Retrieval For Audio-Visual Content
Gyuwon Han, Young Kyun Jang, Chanho Eom Perceptual Artificial Intelligence Lab
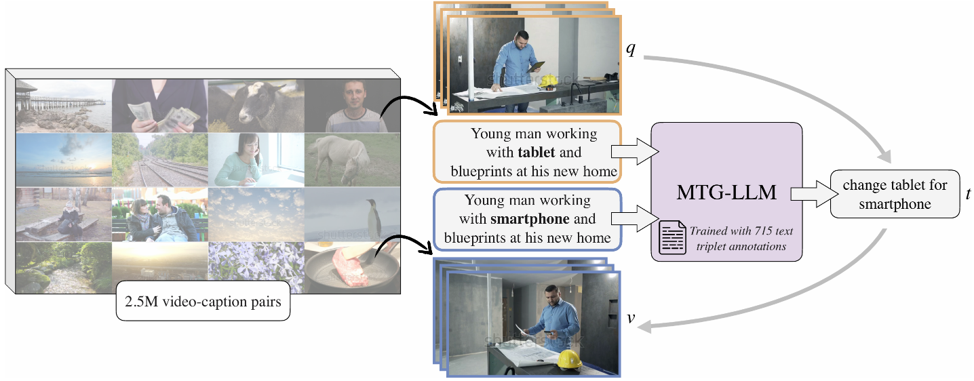
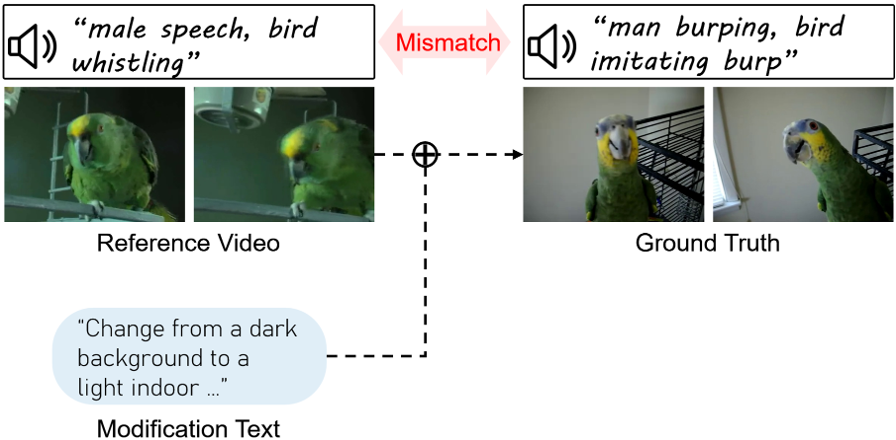
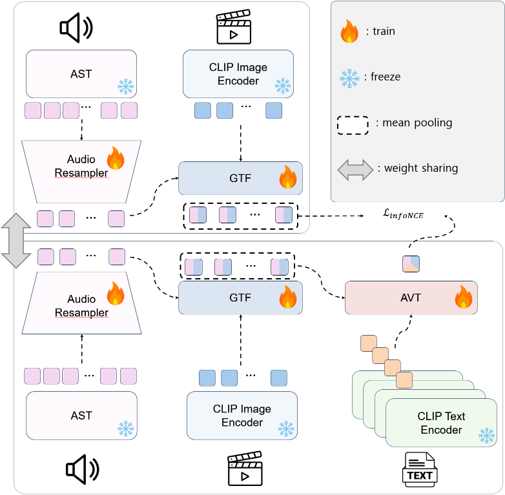
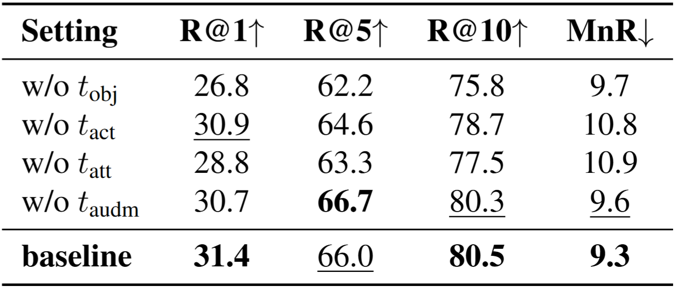
Prior composed video retrieval methods typically focus only on visual modifications, failing to distinguish between videos that are visually similar but differ in their audio content. This limitation leads to a semantic mismatch between user intent and model predictions, especially in scenarios where sound plays a critical role in distinguishing meaning. To address this issue, we introduce a new retrieval task called Composed retrieval for Video with its Audio (CoVA), which considers both visual and auditory changes. We also construct AV-Comp, a high-quality benchmark that consists of video pairs with either visual or auditory differences and corresponding structured textual queries. Each query describes modifications across four aspects: object, action, attribute, and audio, and all samples are human-verified for clarity and accuracy. Furthermore, we propose the AVT Compositional Fusion module, which adaptively integrates video, audio, and text features by adjusting the contribution of each modality based on the semantic intent of the query. Experimental results show that CoVA significantly outperforms simple fusion methods, achieving higher retrieval accuracy and lower mean rank. Finally, AV-Comp serves not only as a benchmark for evaluating CoVA, but also as a diagnostic tool to assess how well existing multimodal models align visual, auditory, and textual information.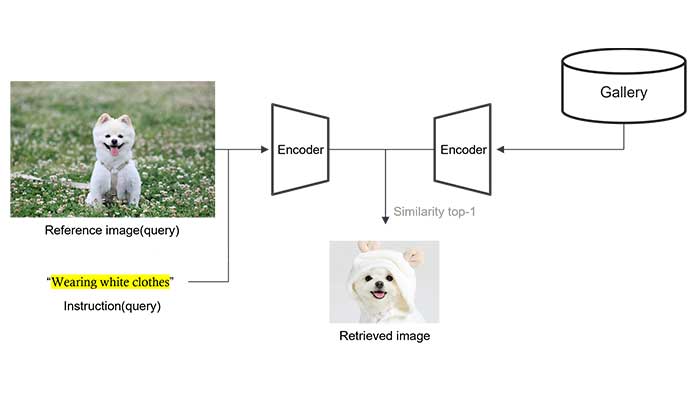

중앙대학교 가상융합대학원

06974 서울특별시 동작구 흑석로 84, 중앙대학교 305관 1001호
Tel. 02-881-7386 / E-mail. caumeta@gmail.com
@ GRADUATE SCHOOL OF METAVERSE CONVERGENCE. ALL RIGHTS RESERVED.