-

- ARCHIVE
MV CIMF Festival
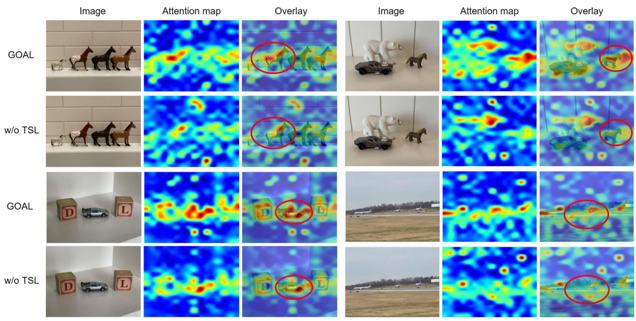
GOAL: Global-local Object Alignment Learning
Hyungyu Choi, Young Kyun Jang, Chanho Eom Perceptual Artificial Intelligence Lab
Vision-language models like CLIP have shown impressive capabilities in aligning images and text, but they oftenstruggle with lengthy and detailed text descriptions becauseof their training focus on short and concise captions. Wepresent GOAL (Global-local Object Alignment Learning),a novel fine-tuning method that enhances CLIP’s ability tohandle lengthy text by leveraging both global and local semantic alignments between image and lengthy text. Ourapproach consists of two key components: Local ImageSentence Matching (LISM), which identifies corresponding pairs between image segments and descriptive sentences, and Token Similarity-based Learning (TSL), whichefficiently propagates local element attention through thesematched pairs. Evaluating GOAL on three new benchmarksfor image-lengthy text retrieval, we demonstrate significant improvements over baseline CLIP fine-tuning, establishing a simple yet effective approach for adapting CLIPto detailed textual descriptions. Through extensive experiments, we show that our method’s focus on local semanticalignment alongside global context leads to more nuancedand representative embeddings, particularly beneficial fortasks requiring fine-grained understanding of lengthy textdescriptions.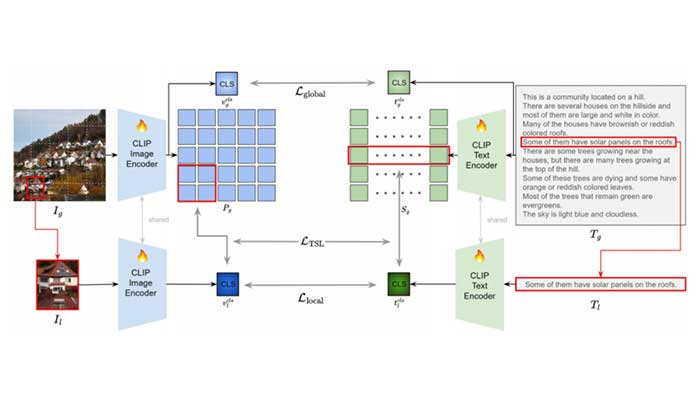




중앙대학교 가상융합대학원

06974 서울특별시 동작구 흑석로 84, 중앙대학교 305관 1001호
Tel. 02-881-7386 / E-mail. caumeta@gmail.com
@ GRADUATE SCHOOL OF METAVERSE CONVERGENCE. ALL RIGHTS RESERVED.