-

- ARCHIVE
MV CIMF Festival

SCENEDERELLA: Text-Driven 3D Scene Generation for Realistic Artboard
Jungmin Lee, Haeun Noh, Jaeyoon Lee, Jongwon Choi Visual Intelligence Lab
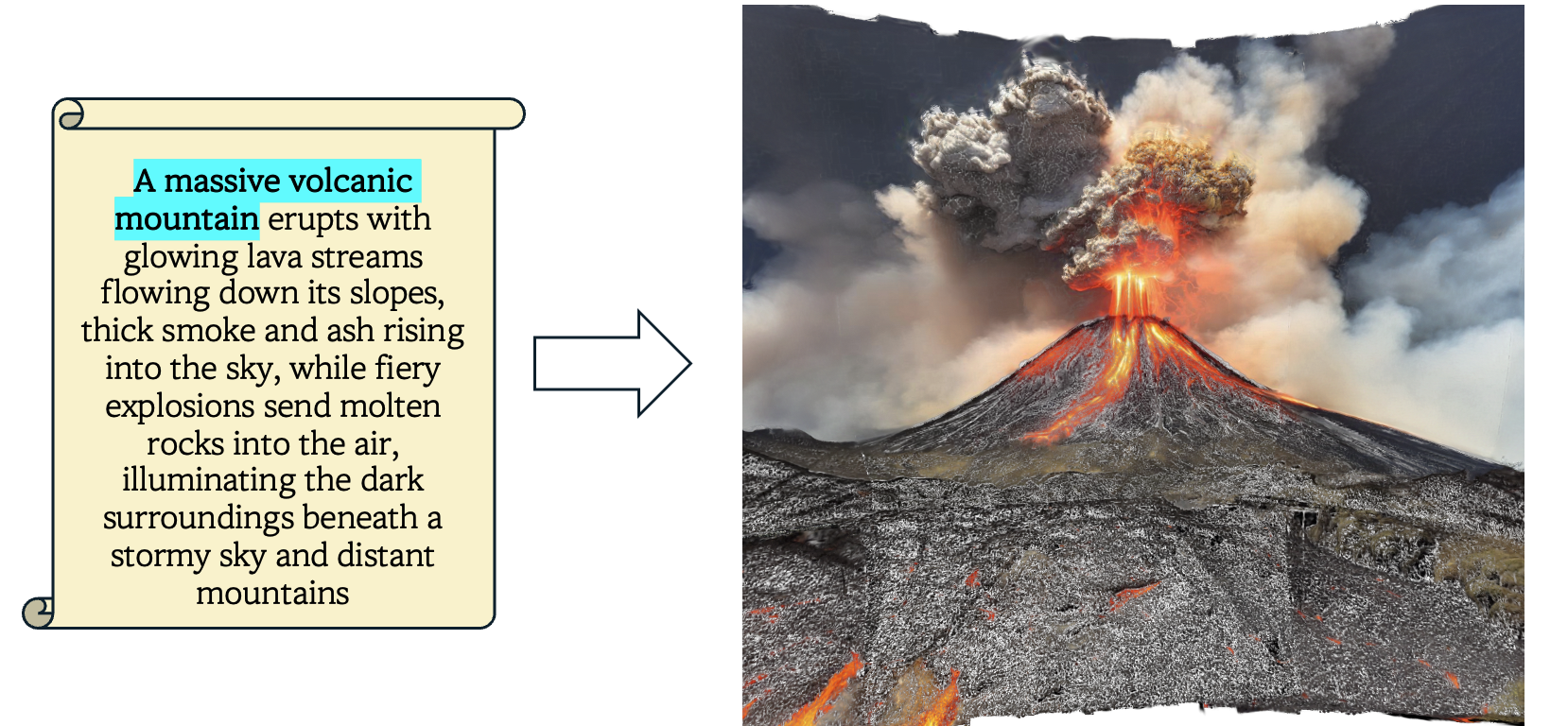
As global media and Video-on-Demand (VOD) markets expand, efficiently producing high-quality 3D scenes has become a key challenge. Our study named SCENEDERELLA generates 3D scenes useful for the film industry using simple text prompts. Since traditional diffusion models create fantastic images, they have limitations in generating scenes truly desired by real-world users. However, fine-tuning the clip encoder of the diffusion model enables the production of realistic 2D scenes for users. Once the initial 2D scenes align with the user's conceptual expectations, we construct 3D scenes using a depth estimator and 3D Gaussian Splatting. The study successfully demonstrates the generation of 3D movie scenes based on various movie scripts. Our method overcomes the limitations of traditional physical set production and offers a new approach that enables the rapid creation of diverse scenes. Additionally, it can be used as a pre-visualization video to attract investment in movies and dramas. Our approach is expected to introduce a new paradigm in content production, with film, gaming, and advertising. Additional results and interactive demos are available at our project website.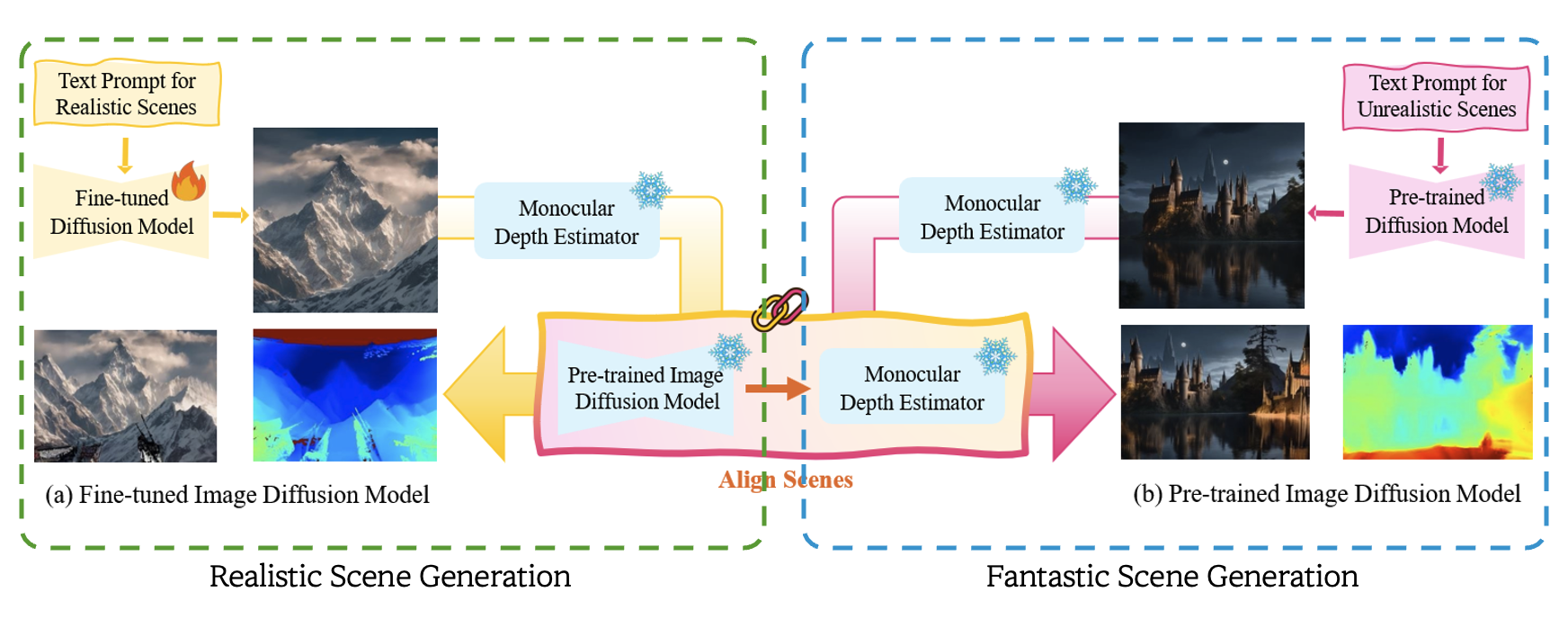


중앙대학교 가상융합대학원

06974 서울특별시 동작구 흑석로 84, 중앙대학교 305관 1001호
Tel. 02-881-7386 / E-mail. caumeta@gmail.com
@ GRADUATE SCHOOL OF METAVERSE CONVERGENCE. ALL RIGHTS RESERVED.