-

- ARCHIVE
MV CIMF Festival



Minsu Kim(Research Scientist) l Google DeepMind, Tokyo, JPN
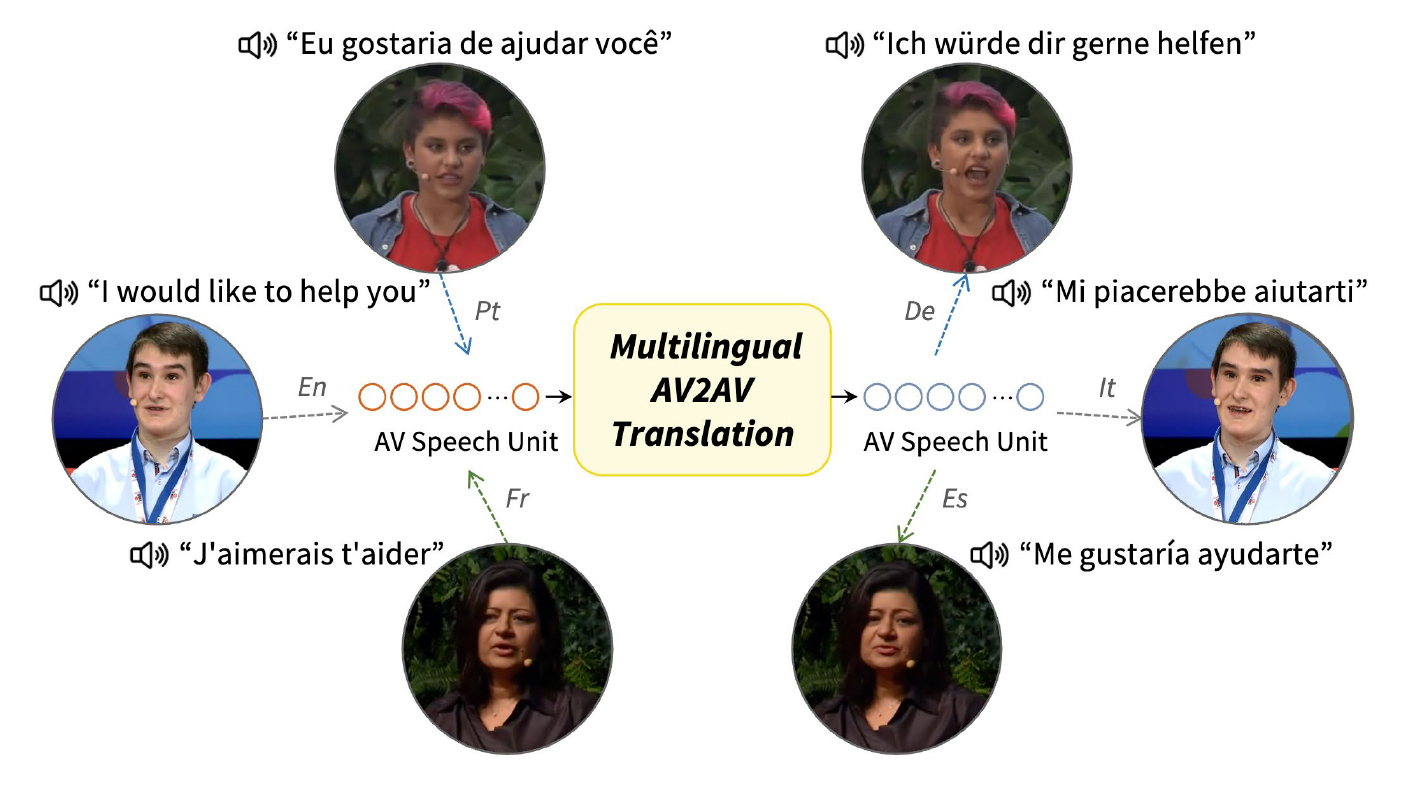
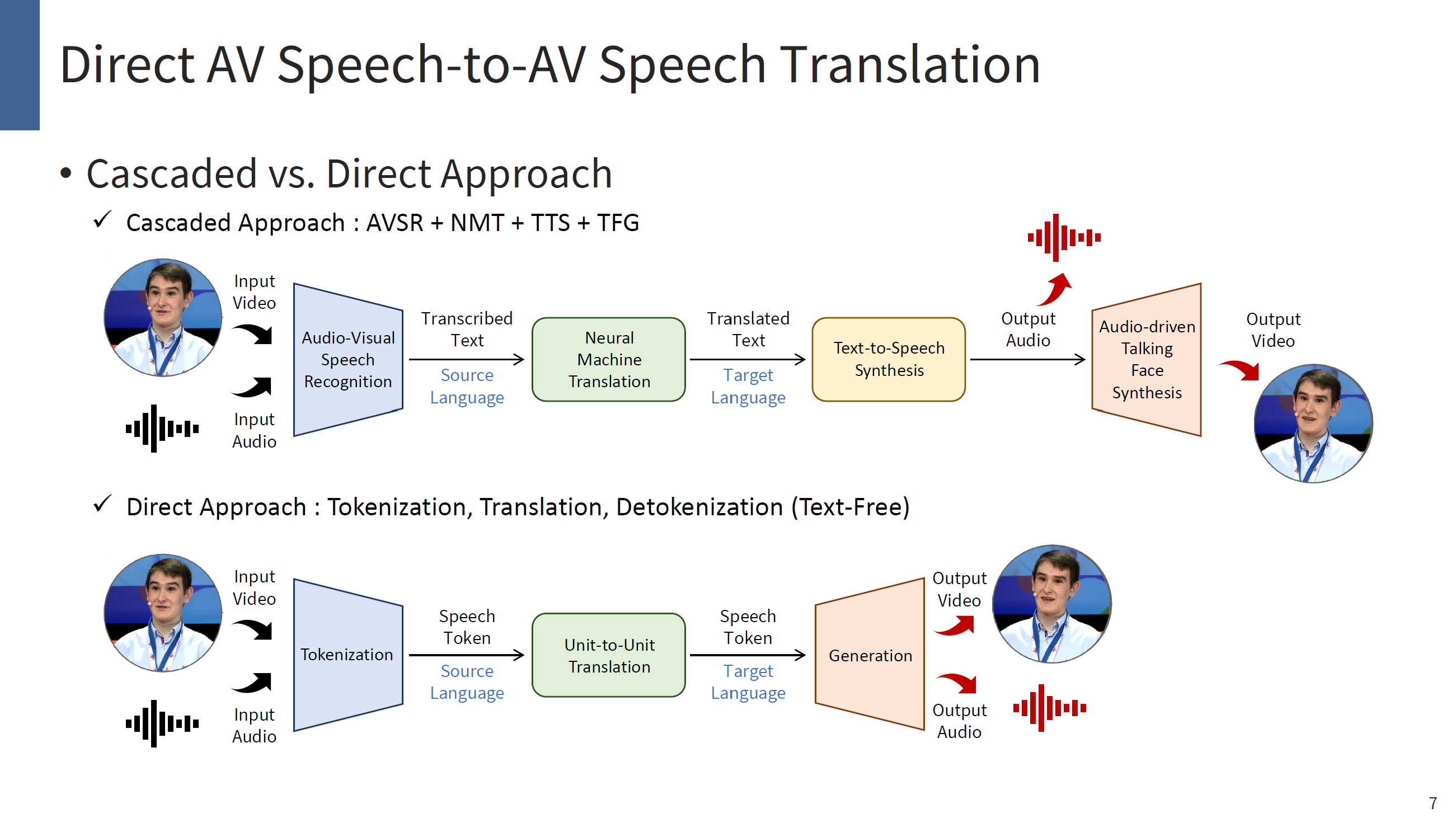
Seamless Communication in the Metaverse: Direct Audio-Visual Speech TranslationLet’s Imagine your self existing in the Metaverse through a Codec Avatar technology. Codec Avatar aims to digitally reconstruct your face and body, allowing you to exist in the VR world as yourself. Therefore, in the VR world, you can meet other people just as you would in real life. Now, imagine you meet a foreigner there, how would you communicate? Since this is a virtual environment, we would like to use our own language. One effective solution is Speech-to-Speech Translation. By translating your speech into the other person’s language, you can communicate seamlessly while still speaking your own language. But what about your avatar’s face, should it continue to reflect your original language? In this presentation, we're gonna see a multi-modal speech-to-speech translation technology, named AV2AV, which simultaneously translates both speech and video modalities into the targeted language. Therefore, with the AV2AV system, we may seamlessly communicate with others by using our own native language in the VR world with the translated voice and lip movements.
06974 서울특별시 동작구 흑석로 84, 중앙대학교 305관 1001호
Tel. 02-881-7386 / E-mail. caumeta@gmail.com
@ GRADUATE SCHOOL OF METAVERSE CONVERGENCE. ALL RIGHTS RESERVED.